
Have you ever faced with slow performance of your application? Have you ever thought of the way to boost your Spring app? If so — then this article is definitely for you. Here we will speak about using super powerful and leading in-memory data grid that may increase your app performance! So let’s jump into this!
What is Hazelcast?
Hazelcast is an operational, in-memory, distributed computing platform for managing data and performing parallel execution for application speed and scale.
Good to know:
- It is written in Java
- Unlike some other in-memory databases — Hazelcast is multiple-threaded, which means it can benefit from all available CPU cores
- Unlike other in-memory data grids — it is designed to be used in distributed environment. It supports unlimited number of maps and caches per cluster
- Based on the benchmarks Hazelcast is up to 56% faster than Redis in getting data, and up to 44% faster than Redis in setting data ?
So it definitely makes sense to get a bit more information about this interesting technology.
And there is really low efforts needed to add it into your Spring Boot project and start using it’s advantages.
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.0.0.RELEASE</version>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>com.hazelcast</groupId>
<artifactId>hazelcast</artifactId>
</dependency>
<dependency>
<groupId>com.hazelcast</groupId>
<artifactId>hazelcast-spring</artifactId>
</dependency>
</dependencies>As you can see, to add Hazelcast to Spring Boot app we need just two dependencies. After that we need to configure Hazelcast instance. There are two ways to do that:
- Through Java configuration
- Through creating hazelcast.xml configuration file
Let’s go with the first option.
package com.config;
import com.hazelcast.config.Config;
import com.hazelcast.config.EvictionPolicy;
import com.hazelcast.config.MapConfig;
import com.hazelcast.config.MaxSizeConfig;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class HazelcastConfiguration {
@Bean
public Config hazelCastConfig(){
Config config = new Config();
config.setInstanceName("hazelcast-instance")
.addMapConfig(
new MapConfig()
.setName("configuration")
.setMaxSizeConfig(new MaxSizeConfig(200, MaxSizeConfig.MaxSizePolicy.FREE_HEAP_SIZE))
.setEvictionPolicy(EvictionPolicy.LRU)
.setTimeToLiveSeconds(-1));
return config;
}
}Since instance is configured — now we can access Hazelcast and manipulate with data.
Hazelcast Controller
For this example I’ll create Hazelcast Controller that will have just 3 mappings:
- One is for settings data
- One is for accessing data by key
- One is for getting all the data from Hazelcast map
Here is the code for our controller:
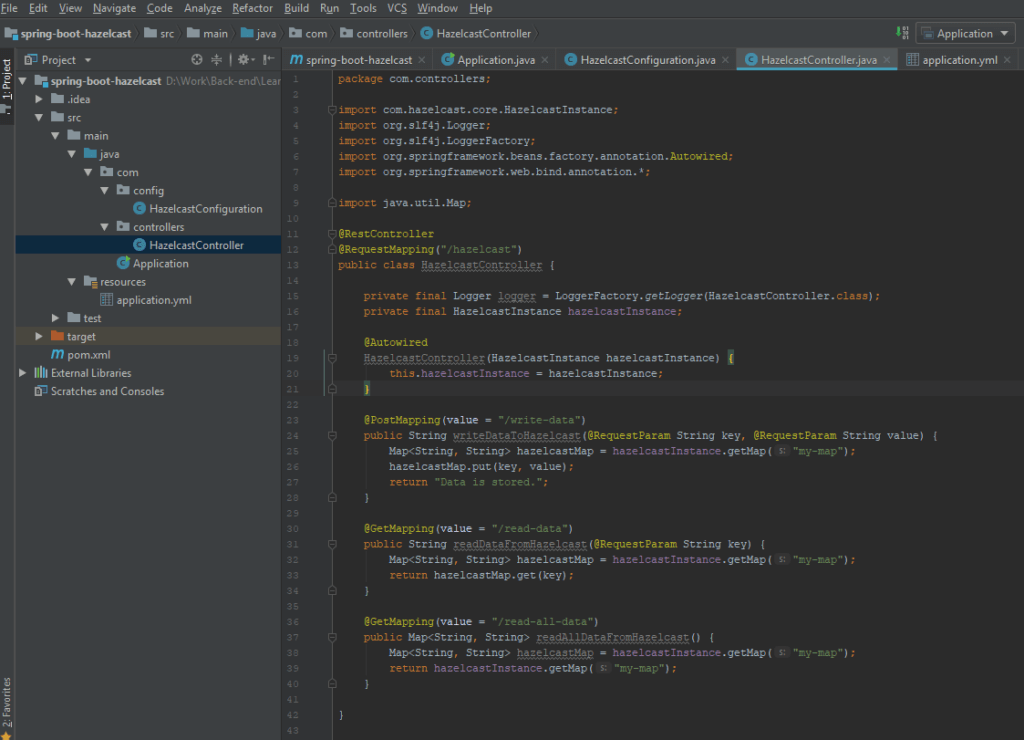
You can see that we have just three java classes in our project, and this is enough to start using Hazelcast.
In the controller we autowired HazelcastInstance — which is the interface provided by Hazelcast library. And by using this instance we can manipulate data in the in-memory data grid. So let’s use Postman to save some records into Hazelcast.
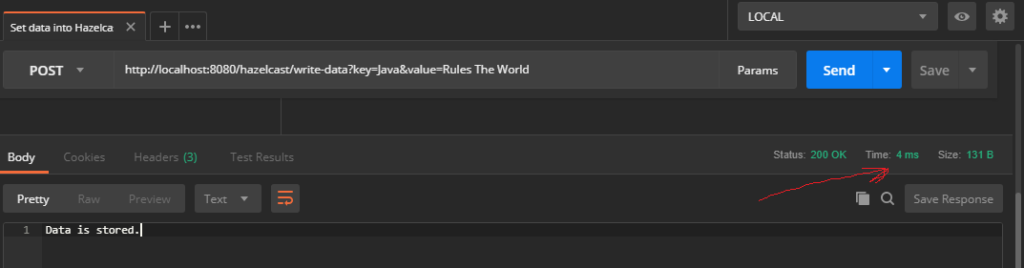
We set an object with key — Java, and it’s value — “Rules The World”. I’ll also add some other key-value pairs, to have more than just one in memory. Important thing here is the speed of writing data. It is just 4 ms!? This is an extremely fast operation!!
And let’s get this data from Hazelcast back:
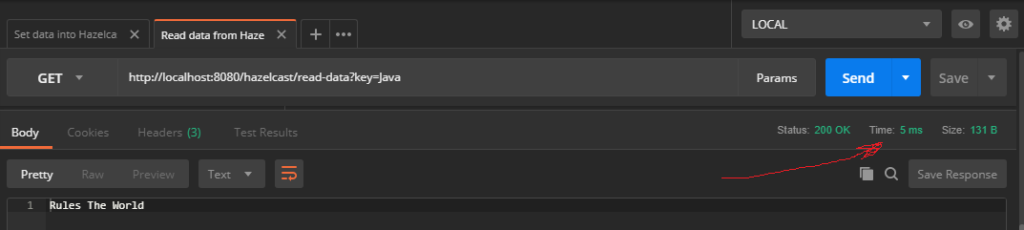
And again — read operation is super fast too. It took us just 5 ms to get data by provided key back from the memory.
One important thing — you can get data stored in this cache even from different application instance. To do this — I’ll change the app port to be 8081, and run another instance of the app, and then will try to fetch all the data from Hazelcast that we stored before.
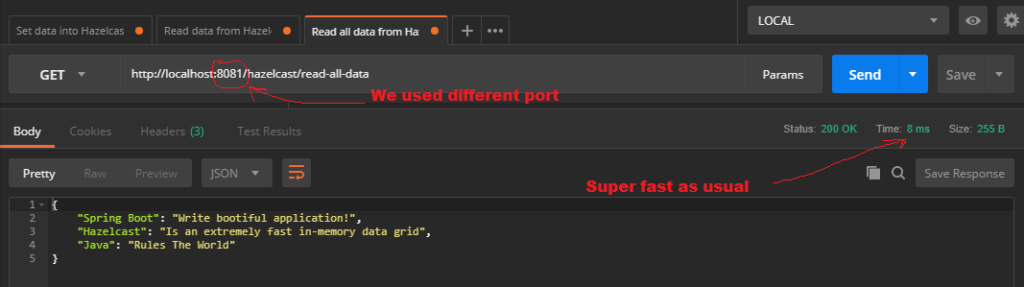
As you can see we made a request to second instance of our server app, that we just run. It’s serving on 8081 port. And eventhough we haven’t put something to Hazelcast using this new instance, but we can fetch everything that was stored in Hazelcast using another application instance. So it’s clustered, and data may be shared among many and many application instances.
And even if we stopped our first instance, that was running on 8080 port, data is not lost. It is still available by making a request to the instance on 8081 port.
Conclusion
So using Hazelcast as an in-memory data grid is really useful and opinionated if you take care about the performance, speed of your read-write operations and you want to make sure your data is stored correctly and failing of one your standalone application or microservice will not lead to data lost.

Thank you for your time! Hope you enjoyed the reading and got some useful tips on Spring Boot with Hazelcast.
All the code available on my personal GitHub repo.
It is always fun and pleasure to write articles and help others to better understand new technologies.
Want to get updates on upcoming articles? Follow me on LinkedIn and Twitter ?




